Jsoup爬取网页内容

Jsoup爬取网页内容
产品中有获取网络新闻的功能,使用的三方API接口,之前一直都是免费的,现在开始收费了...
功能不能丢,找来找去找不到合适的API,遂想着能不能自己做一个获取新闻的,于是研究了研究Jsoup,在这里记录一下
简介
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。官网:https://jsoup.org/
主要功能
- 从一个URL,文件或字符串中解析HTML
- 使用DOM或CSS选择器来查找、取出数据
- 可操作HTML元素、属性、文本
使用
准备工作
此次需要获取新闻,也只是简单的获取到了标题和链接等信息,依赖于网页的 HTML信息,若网页做了更改,则获取可能会失效。获取网页中的内容,首先得找到一个合适的目标网页,这里我获取的是新浪新闻内容。新闻中心首页_新浪网 。由于需要获取指定内容,所以使用的是搜索后的列表页,具体URL为:
https://search.sina.com.cn/?q=海贼王&c=news&sort=time
参数说明:
p: 此参数为搜索内容
sort:此参数为排序方式,可选time为按时间排序,rel为按相关度排序
分析目标网页
确认需要获取的内容,此处我需要标题和新闻发布时间,以及新闻的url
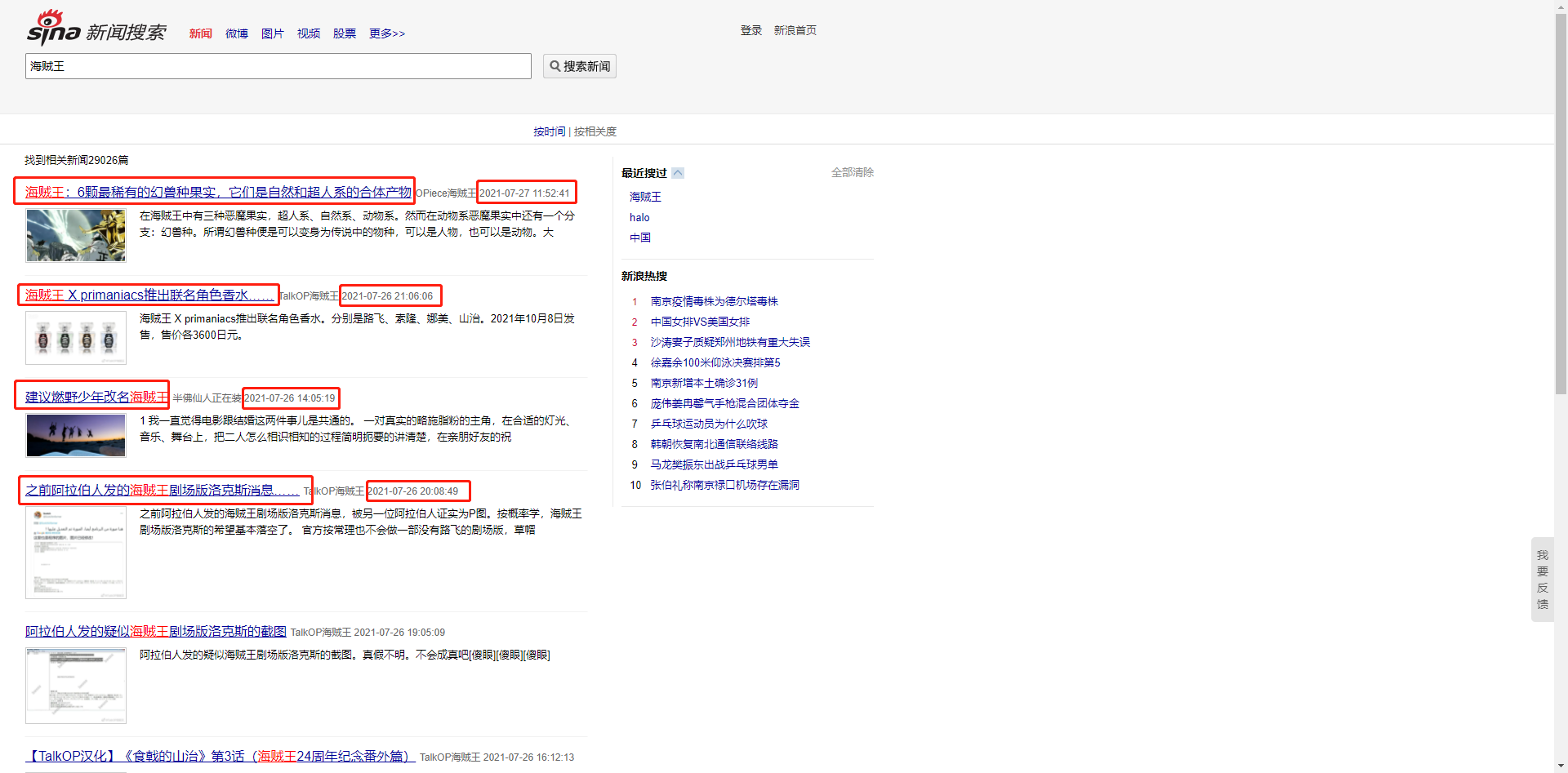
··
按F12进一步进行分析,或者直接在需要的元素上面右键选择检查就可以看到我们需要的内容位于HTML什么地方。
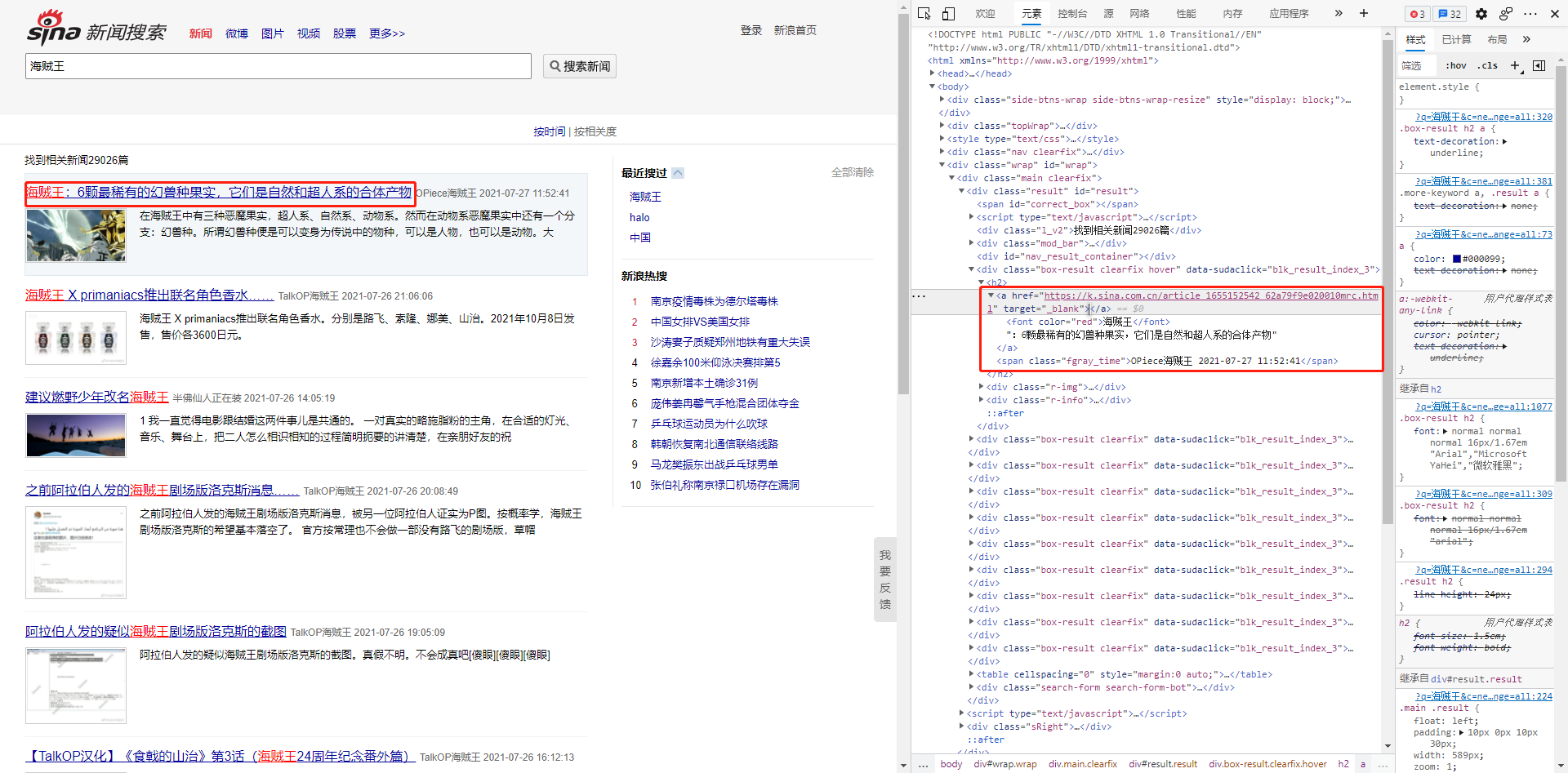
可以看到我们需要的内容都在这个h2标签里了,下面开始进行获取
引入依赖
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
</dependencies>
开始
使用Jsoup加载网页内容,并返回Document对象,加载HTML有多种方式,可根据需要进行选择。
-
从URL加载
//1.使用connect方式 Document document = Jsoup.connect("https://search.sina.com.cn/?q=海贼王&c=news&sort=time").get(); //2.使用parse方式 String url="hhttps://search.sina.com.cn/?q=海贼王&c=news&sort=time"; Document document = Jsoup.parse(new URL(url), 30000); //30000表示 timeoutMillis -
从字符串中加载
String html = "<html><head><title>First parse</title></head>" + "<body><p>Hello World.</p></body></html>"; Document document = Jsoup.parse(html); -
从文件加载
Document document = Jsoup.parse(new File("F:\\jsoup\\html\\index.html"),"utf-8");
我们获取到Document对象后,就可以使用Document的方法获取需要的内容,Document方法属性和JavaScript 中的Document节点是差不多,不了解的可以看看Document 节点 - JavaScript 教程 - 网道 (wangdoc.com)
根据网页源代码,可以看到我们需要的所有查询结果均位于 id=result的div中,我们就可以通过getElementById()获取这个div节点。
Element element = document.getElementById("result");
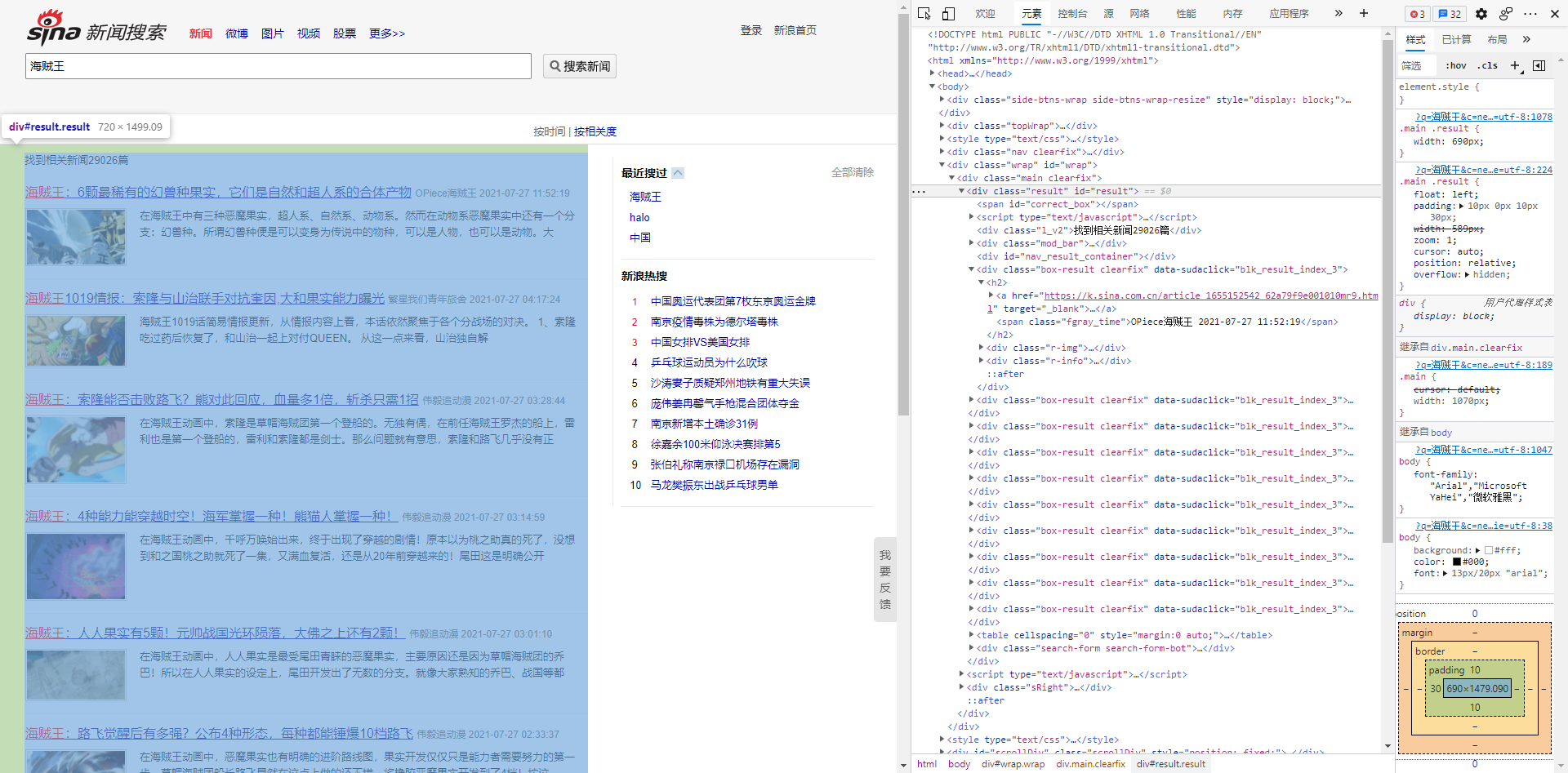
再依次获取其他内容即可
完整代码
package TestNews;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
public class TestNews {
public static void main(String[] args) throws Exception {
getSinaNews("海贼王");
}
public static void getSinaNews(String keyword) throws IOException {
//获取Dcoument对象
String url="https://search.sina.com.cn/?c=news&from=channel&ie=utf-8&q="+keyword;
Document document = Jsoup.parse(new URL(url), 30000);
//获取搜索结果div
Element element = document.getElementById("result");
//获取结果列表
Elements elements = element.getElementsByClass("box-result clearfix");
//循环获取
for (Element e : elements) {
String newsHtml = e.getElementsByTag("a").eq(0).attr("href");
//说明:这里我需要新闻具体内容,所以这里又根据获取到的文章url,获取了详情页的Documenet,再获取了详情页的内容
Document news = Jsoup.parse(new URL(newsHtml), 30000);
System.out.println(newsHtml);
String title = news.getElementsByClass("main-title").eq(0).text();
System.out.println(title);
String date = news.getElementsByClass("top-bar-inner clearfix").first().getElementsByClass("date").eq(0).text();
System.out.println(date);
Elements elementsByTag = news.getElementsByClass("article-content-left").first().getElementsByClass("article").first().getElementsByTag("p");
for (Element element1 : elementsByTag) {
String text = element1.text();
System.out.println(text);
}
List<String> imageUrls=new ArrayList<String>();
Elements images = news.getElementsByClass("article-content-left").first().getElementsByClass("article").first().getElementsByClass("img_wrapper");
for (Element image : images) {
imageUrls.add(image.getElementsByTag("img").attr("src"));
}
System.out.println(imageUrls.toString());
System.out.println("****************************************************");
}
}
}
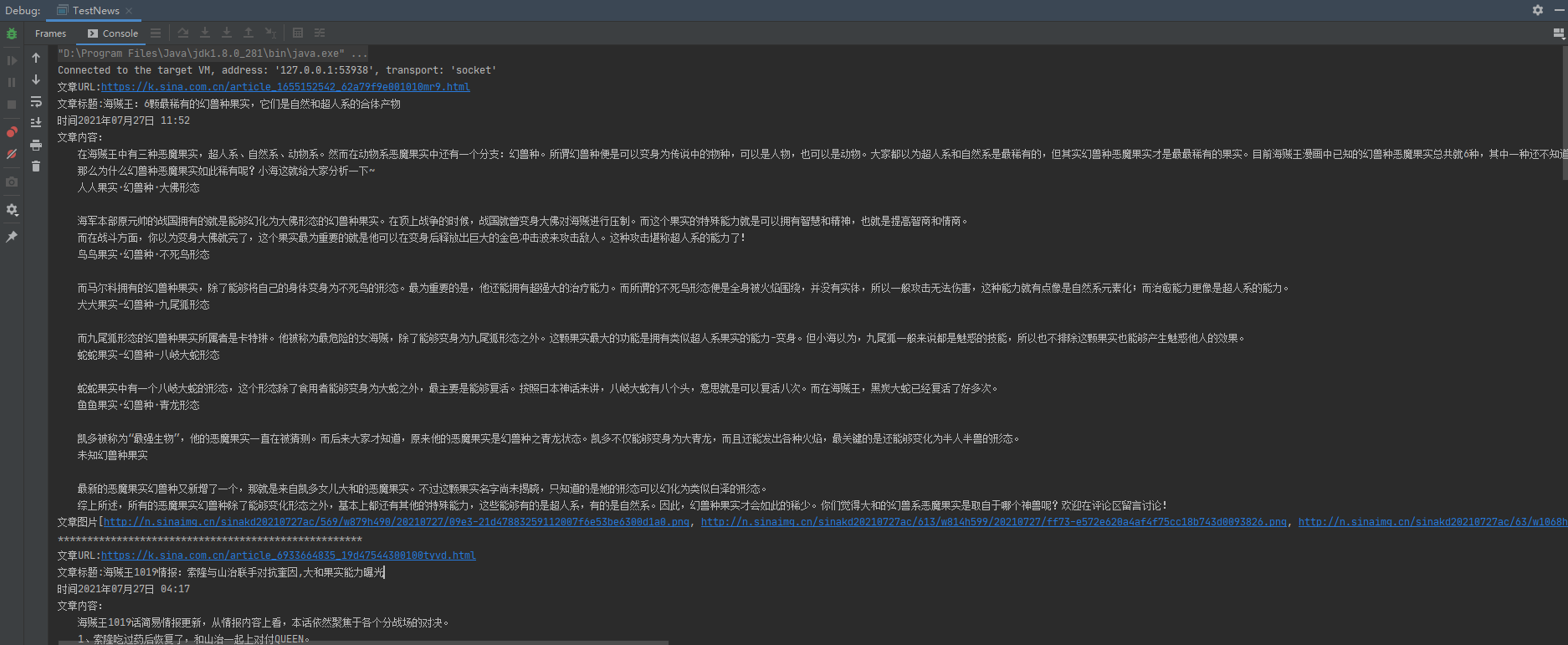
打印结果:
文章URL:https://k.sina.com.cn/article_1655152542_62a79f9e001010mr9.html
文章标题:海贼王:6颗最稀有的幻兽种果实,它们是自然和超人系的合体产物
时间2021年07月27日 11:52
文章内容:
在海贼王中有三种恶魔果实,超人系、自然系、动物系。然而在动物系恶魔果实中还有一个分支:幻兽种。所谓幻兽种便是可以变身为传说中的物种,可以是人物,也可以是动物。大家都以为超人系和自然系是最稀有的,但其实幻兽种恶魔果实才是最最稀有的果实。目前海贼王漫画中已知的幻兽种恶魔果实总共就6种,其中一种还不知道名字。
那么为什么幻兽种恶魔果实如此稀有呢?小海这就给大家分析一下~
人人果实·幻兽种·大佛形态
海军本部原元帅的战国拥有的就是能够幻化为大佛形态的幻兽种果实。在顶上战争的时候,战国就曾变身大佛对海贼进行压制。而这个果实的特殊能力就是可以拥有智慧和精神,也就是提高智商和情商。
而在战斗方面,你以为变身大佛就完了,这个果实最为重要的就是他可以在变身后释放出巨大的金色冲击波来攻击敌人。这种攻击堪称超人系的能力了!
鸟鸟果实·幻兽种·不死鸟形态
而马尔科拥有的幻兽种果实,除了能够将自己的身体变身为不死鸟的形态。最为重要的是,他还能拥有超强大的治疗能力。而所谓的不死鸟形态便是全身被火焰围绕,并没有实体,所以一般攻击无法伤害,这种能力就有点像是自然系元素化;而治愈能力更像是超人系的能力。
犬犬果实-幻兽种-九尾狐形态
而九尾狐形态的幻兽种果实所属者是卡特琳。他被称为最危险的女海贼,除了能够变身为九尾狐形态之外。这颗果实最大的功能是拥有类似超人系果实的能力-变身。但小海以为,九尾狐一般来说都是魅惑的技能,所以也不排除这颗果实也能够产生魅惑他人的效果。
蛇蛇果实-幻兽种-八岐大蛇形态
蛇蛇果实中有一个八岐大蛇的形态,这个形态除了食用者能够变身为大蛇之外,最主要是能够复活。按照日本神话来讲,八岐大蛇有八个头,意思就是可以复活八次。而在海贼王,黑炭大蛇已经复活了好多次。
鱼鱼果实·幻兽种·青龙形态
凯多被称为“最强生物”,他的恶魔果实一直在被猜测。而后来大家才知道,原来他的恶魔果实是幻兽种之青龙状态。凯多不仅能够变身为大青龙,而且还能发出各种火焰,最关键的是还能够变化为半人半兽的形态。
未知幻兽种果实
最新的恶魔果实幻兽种又新增了一个,那就是来自凯多女儿大和的恶魔果实。不过这颗果实名字尚未揭晓,只知道的是她的形态可以幻化为类似白泽的形态。
综上所述,所有的恶魔果实幻兽种除了能够变化形态之外,基本上都还有其他的特殊能力,这些能够有的是超人系,有的是自然系。因此,幻兽种果实才会如此的稀少。你们觉得大和的幻兽系恶魔果实是取自于哪个神兽呢?欢迎在评论区留言讨论!
文章图片[http://n.sinaimg.cn/sinakd20210727ac/569/w879h490/20210727/09e3-21d47883259112007f6e53be6300d1a0.png, http://n.sinaimg.cn/sinakd20210727ac/613/w814h599/20210727/ff73-e572e620a4af4f75cc18b743d0093826.png, http://n.sinaimg.cn/sinakd20210727ac/63/w1068h595/20210727/8666-d2895bec021f06753678fe0913bf5eb6.png, http://n.sinaimg.cn/sinakd20210727ac/98/w1089h609/20210727/6033-dbec536624700f6cc98c9f63be118bed.png, http://n.sinaimg.cn/sinakd20210727ac/90/w1085h605/20210727/f84d-f28bd8f9866cb640ab5069ffffd84d0a.png, http://n.sinaimg.cn/sinakd20210727ac/784/w1053h531/20210727/46bc-0724c348468dd73e6e61326a2165bd46.png]
****************************************************
至此简单的获取就可以了,可以再根据需要,将所需数据存入数据库。但是面对javascript动态生成的网页,是无法解析的,可以使用HtmlUnit配合jsoup来解决,后面有时间再研究吧。